
De vez en cuando surge la pregunta: «¿Después de IPv4 viene IPv6, y luego IPv8?» Sin embargo, no existe ninguna especificación formal de IPv8. El campo de versión de IPv4 tiene 4 bits, con valores del 0 al 15. IPv5 fue ocupado en 1979 por el Internet Stream Protocol (ST), e IPv6 eligió deliberadamente ser incompatible con IPv4. Han surgido propuestas para IPv7 y versiones posteriores, pero ninguna ha sido estandarizada por la IETF.
Entonces, ¿qué se está investigando y estandarizando realmente como «protocolo de próxima generación»? ¿Cómo abordan los problemas que planteó IPv4? Este artículo pretende aclarar la realidad.
IPv4 sigue en servicio, pero los problemas se acumulan
Primero, revisemos el estado actual. Las direcciones IPv4 no asignadas de la IANA se agotaron en 2011. Sin embargo, en la práctica, NAT, CGNAT, CDN, proxies y el mercado de transferencia de direcciones han permitido que todo siga funcionando.
La adopción de IPv6 varía enormemente entre países.
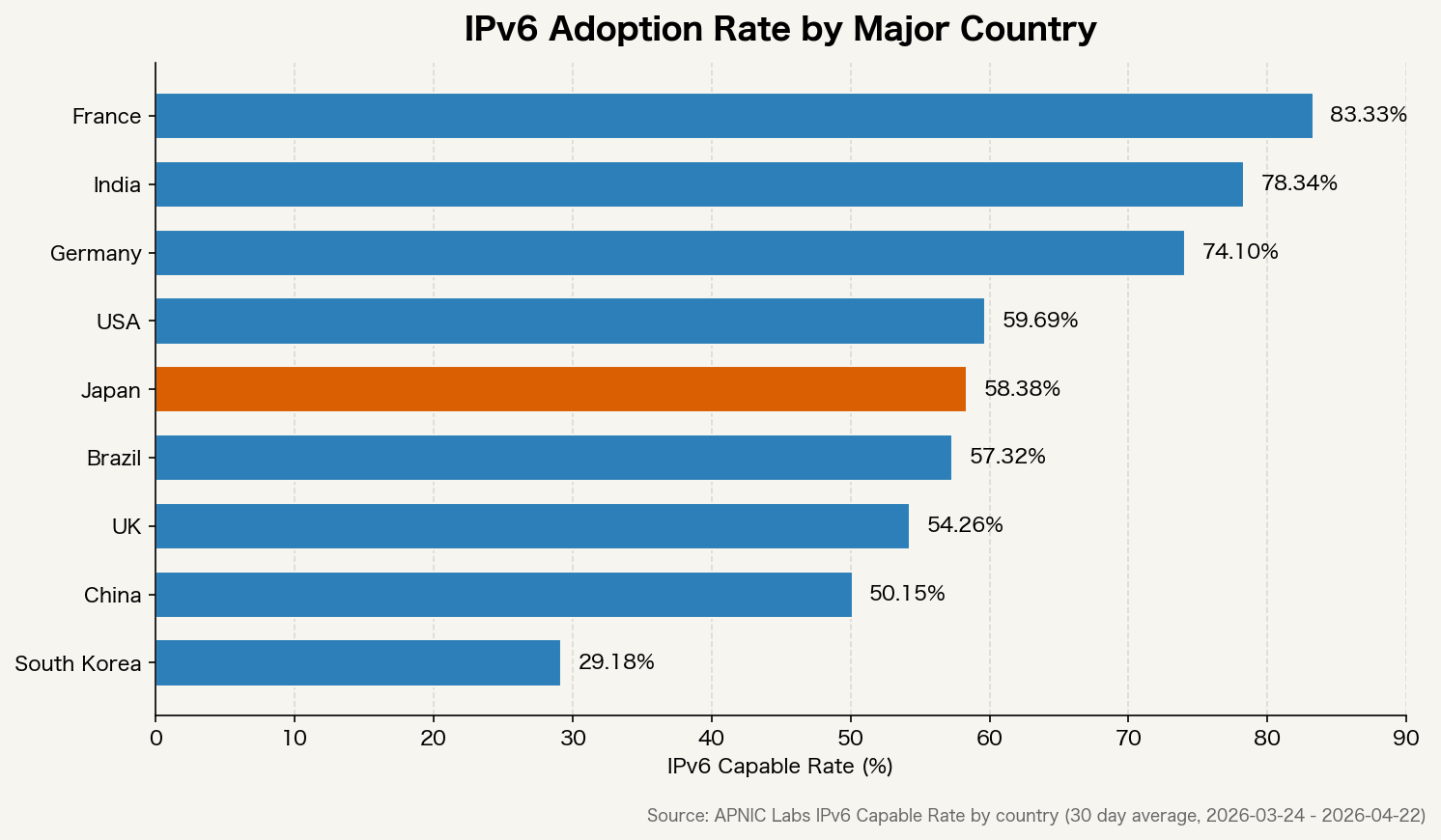
Francia e India han alcanzado el 70–90%, mientras que Japón y Corea del Sur se mantienen por debajo del 50%. La lenta adopción de IPv6 no es un problema de estándares — es que «con NAT nos las arreglamos por ahora», por lo que la migración nunca se convierte en una prioridad.
Las velocidades de banda ancha fija también varían considerablemente entre países.
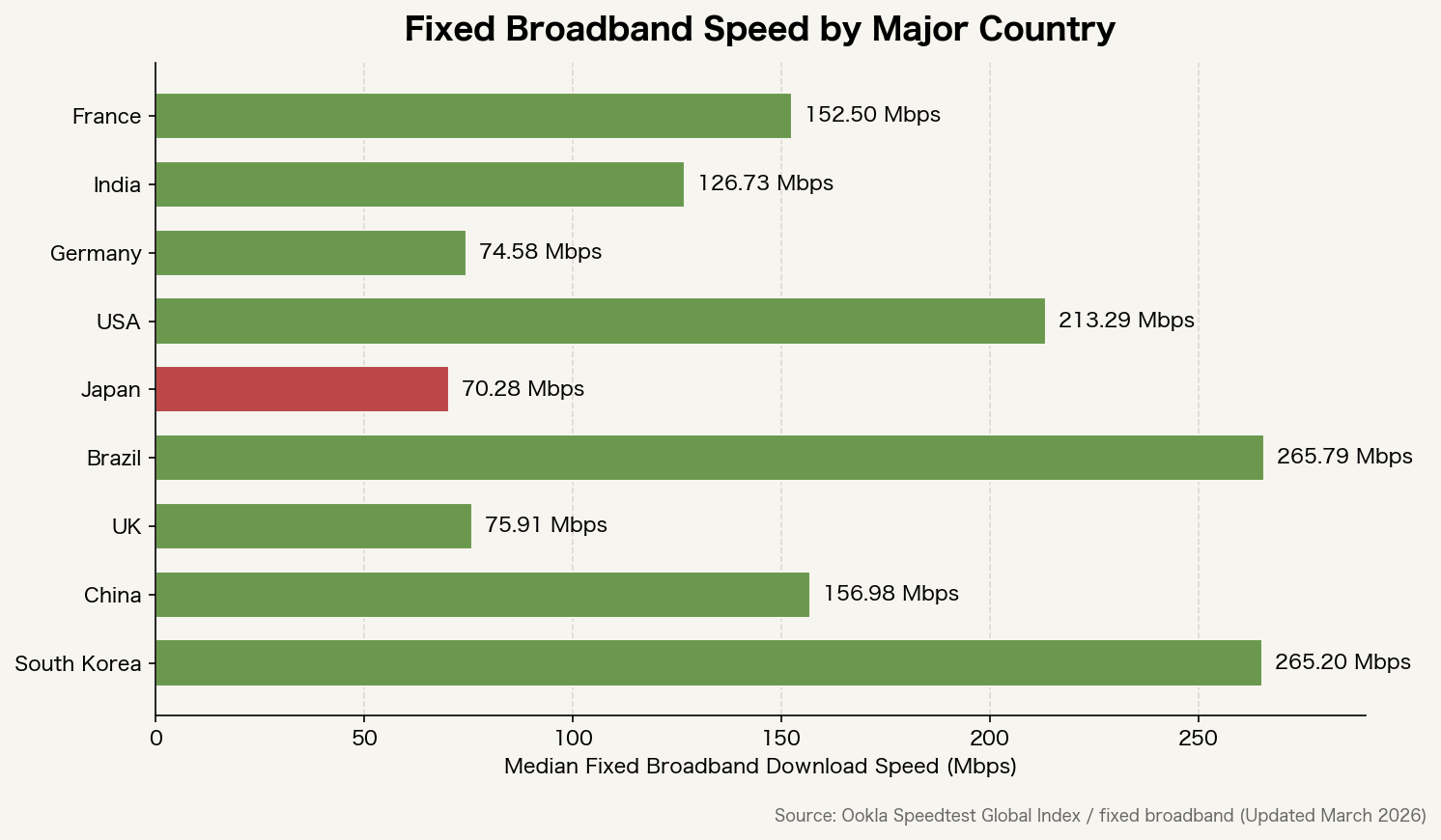
La principal causa de las diferencias de velocidad es la inversión en infraestructura, pero las capas adicionales de NAT y proxies sí acumulan latencia. Cuantas más soluciones provisionales acumule IPv4, menos simple se vuelve la ruta de enrutamiento.
Por qué IPv6 eligió una «ruptura limpia» — y el precio de esa decisión
IPv6 abandonó la compatibilidad con versiones anteriores de IPv4. Fue una decisión deliberada. Además de ampliar la longitud de las direcciones de 32 a 128 bits, rediseñó las estructuras de cabecera y buscó restaurar la conectividad extremo a extremo sin depender de NAT.
Pero esta «ruptura limpia» creó fricción en la migración. El período de doble pila — ejecutar IPv4 e IPv6 en paralelo — se prolongó, requiriendo doble gestión de monitorización, cortafuegos, análisis de registros y listas de permisos. Los costes aumentaron mientras los beneficios visibles para los usuarios finales seguían siendo escasos. Era fácil decir «no hay razón convincente para hacerlo ahora».
Esta lección planteó la pregunta: ¿podría IPv4 ampliarse manteniendo la compatibilidad? Ese pensamiento condujo a SRv6 y diversas tecnologías de transición.
SRv6: extendiendo IPv6 para encapsular también IPv4
SRv6 (Segment Routing over IPv6) utiliza cabeceras de extensión de IPv6 para especificar explícitamente las rutas de enrutamiento de paquetes. Está estandarizado como RFC 8986.
La clave es que los paquetes IPv4 pueden encapsularse dentro de SRv6 para su reenvío, lo que significa que el tráfico IPv4 puede circular sobre la lógica de enrutamiento de IPv6. Es una aproximación al concepto de «superconjunto de IPv4» implementado como extensión de IPv6.
SRv6 aborda varios desafíos:
- Control de rutas sin etiquetas MPLS (reduce la complejidad de la pila de etiquetas)
- Ingeniería de tráfico de grano fino por ruta
- Enrutamiento unificado a través de los límites de redes cloud y de operadores
- Un único plano de reenvío para entornos mixtos IPv4/IPv6
NTT, China Telecom, Alibaba y otros lo están desplegando comercialmente, especialmente para interconexiones de centros de datos a gran escala y redes centrales 5G.
SCION: rediseñando el enrutamiento desde cero
Mientras SRv6 extiende IPv6, SCION (Scalability, Control, and Isolation On Next-generation networks) apunta a un rediseño más fundamental. Liderado por la ETH Zürich, fue presentado en IEEE Security & Privacy 2011.
La idea central de SCION es dar al emisor el control sobre las rutas de enrutamiento. El internet actual usa BGP (Border Gateway Protocol) para determinar las rutas, y los emisores no tienen control sobre qué camino toman sus paquetes. Con SCION, los emisores pueden especificar rutas explícitamente.
Esto permite:
- Prevenir cambios de ruta arbitrarios por parte de ISP o gobiernos (defensa contra secuestro de rutas)
- Rutas elegidas por el emisor según latencia, ancho de banda y fiabilidad
- Fallos localizados en sistemas autónomos (AS) específicos
- Autenticación integrada en la arquitectura, lo que dificulta la suplantación
La red suiza de gobierno e instituciones financieras «SSFN» (Swiss Secure Finance Network) la ejecuta en producción. También puede funcionar como superposición sobre IPv4/IPv6, permitiendo la coexistencia con la infraestructura existente.
NDN: enrutamiento por nombre de contenido, no por dirección IP
NDN (Named Data Networking) propone enrutar paquetes por nombre de contenido en lugar de por dirección. Es uno de los proyectos de Future Internet Architecture financiados por la NSF (National Science Foundation).
El internet actual está diseñado en torno a «a qué host enviar». NDN se centra en «qué recuperar». El contenido se nombra y el enrutamiento se realiza por ese nombre.
Esto permite:
- Almacenamiento en caché en red de contenidos idénticos — funcionalidad similar a CDN en la capa de infraestructura
- Integridad vinculada a nombres, facilitando la detección de manipulaciones
- Traspaso natural en entornos móviles sin dependencia de la dirección de origen
Sin embargo, la compatibilidad con la infraestructura IP existente es baja y las perspectivas de adopción a corto plazo son poco claras. Se está progresando en la adopción parcial en IoT y computación en el borde.
QUIC/HTTP3: absorbiendo las diferencias de versión IP en una capa superior
En lugar de cambiar la arquitectura, otro enfoque absorbe las diferencias de versión IP en una capa superior. QUIC (RFC 9000) ejemplifica esto.
QUIC funciona sobre UDP y no utiliza directamente el par dirección IP/puerto como identificador de conexión. En su lugar, usa un ID de conexión específico de la conexión, por lo que las conexiones persisten incluso cuando cambia la dirección IP.
Esto proporciona a las capas superiores la misma calidad de comunicación tanto sobre IPv4 como sobre IPv6. HTTP/3 funciona sobre QUIC. La mayoría de los principales navegadores y servidores ya lo admiten.
¿Hasta qué punto se ha logrado la «compatibilidad ascendente de IPv4»?
La realización práctica más cercana a la «compatibilidad ascendente de IPv4» es la combinación de SRv6 y tecnologías de transición como MAP-T.
MAP-T (Mapping of Address and Port using Translation, RFC 7599) reenvía paquetes IPv4 a través de una red IPv6 y los convierte de vuelta a IPv4 en la salida. Los extremos pueden permanecer en IPv4 mientras el backbone migra a IPv6.
Combinando estas tecnologías se crea una configuración funcional donde:
- Los usuarios finales continúan usando IPv4
- La red central se diseña sobre IPv6
- El control de rutas se unifica bajo SRv6
No se necesita un nuevo número de versión llamado «IPv8» — los estándares existentes combinados pueden alcanzar un objetivo similar.
Lo que está ocurriendo realmente ahora
Más allá de la investigación y los estándares, esto es lo que realmente está en marcha hoy:
- 5G SA (Standalone): El diseño de la red central es nativo de IPv6. Integrado en los estándares de 3GPP
- Despliegue comercial de SRv6: China Telecom, NTT, Softbank y otros lo han adoptado para sus redes troncales nacionales
- SCION en producción: Funcionando en la red financiera suiza (SSFN)
- Revisión de App Store de Apple: Requiere verificación de funcionamiento en entornos solo IPv6, forzando el cumplimiento en el lado de las apps
- Cloudflare / Google: La proporción de tráfico IPv6 sigue aumentando año tras año; absorber IPv4/IPv6 en el borde es ahora estándar
La «próxima versión» de IP no aparecerá como un único nuevo estándar. Serán estas tecnologías reemplazando gradualmente cada capa.
Lo que se puede hacer ahora es reducir poco a poco la dependencia de las direcciones IP: dejar de usar listas de permisos de IP fijas, migrar a autenticación basada en certificados e identidades, usar DNS correctamente y aprovechar CDN y el borde. Esa preparación funciona independientemente del protocolo de próxima generación que llegue.
Opinión personal: extender IPv4 a 8 octetos habría sido mejor
Permítanme añadir una opinión personal al final.
Al ver que han pasado casi 30 años sin una migración significativa desde que IPv6 eligió una «ruptura limpia», me pregunto si la dirección del diseño fue simplemente incorrecta.
Lo que creo que habría sido ideal es extender la notación de direcciones de IPv4 a 8 octetos.
255.255.255.255.255.255.255.255Es decir, extender el x.x.x.x actual (32 bits) a x.x.x.x.x.x.x.x (64 bits).
El espacio de direcciones se amplía drásticamente
IPv4 de 32 bits proporciona aproximadamente 4.300 millones de direcciones. 64 bits proporciona aproximadamente 18.400 trillones de direcciones (2⁴). Incluso con 35.000 millones de dispositivos IoT, eso es más que el número de granos de arena en la Tierra — no hay necesidad de mantener NAT con vida.
La compatibilidad con versiones anteriores es más fácil de mantener
Tratar las direcciones IPv4 existentes como 0.0.0.0.x.x.x.x significa que los paquetes IPv4 actuales funcionan como un subconjunto del nuevo protocolo. Los routers podrían reenviar las direcciones donde los 4 octetos superiores son 0.0.0.0 como compatibles con IPv4. El turbulento período de doble pila podría haberse acortado drásticamente.
La notación legible por humanos se preserva
2001:0db8:85a3:0000:0000:8a2e:0370:7334 de IPv6 es incómodo para la resolución de problemas en campo, revisión de registros y escritura de reglas de cortafuegos. La notación de 8 octetos sería legible para cualquiera familiarizado con IPv4.
# IPv4 actual
192.168.1.100
# Propuesta de 8 octetos extendidos
0.0.0.0.192.168.1.100 (espacio de compatibilidad IPv4)
10.48.0.0.192.168.1.100 (ejemplo de nuevo espacio de direcciones global)Existen desafíos prácticos
- 64 bits podría no ser suficiente para el IoT masivo del futuro o las redes de agentes de IA (los 128 bits de IPv6 contemplan esto)
- La lógica de procesamiento de direcciones de los routers necesitaría cambiar — un cambio pesado para el hardware de los años 90
- Las características de seguridad (autenticación, cifrado) no se resuelven solo con la extensión de direcciones
Aun así, la idea de «solo aumentar el número de octetos sin cambiar la notación» parece que podría haber sido una opción realista, dados los costes de migración de IPv6 que no se extendió en 30 años.
Los diseñadores de IPv6 sin duda entendieron este dilema, y tuvieron razones para elegir la ruptura limpia de todas formas. Pero el resultado es que la mitad del mundo todavía funciona con IPv4. Ese hecho tiene peso.
Opinión personal: el cuello de botella del NAT también es un problema del cobre
Hay una perspectiva más que quiero añadir.
El cuello de botella del NAT no es solo el coste de procesamiento de la traducción de direcciones. El problema fundamental es que los equipos de red actuales, cada vez que reciben una señal transportada por fibra óptica, la convierten a señal eléctrica antes de procesarla. Las señales eléctricas generan calor, sufren interferencias y se degradan. La traducción NAT también ocurre en estos circuitos eléctricos, por lo que los límites se hacen evidentes a medida que aumenta el número de sesiones.
La iniciativa IOWN (Innovative Optical and Wireless Network) de NTT, y su componente central la APN (All-Photonics Network), pretende repensar esta estructura desde sus fundamentos.
La arquitectura convencional es así:
Fibra óptica → [conversión E/O] → Router (procesamiento eléctrico) → [conversión O/E] → Fibra ópticaLo que APN aspira a lograr es esto:
Fibra óptica → Router (procesamiento óptico) → Fibra ópticaSe establece un «camino de longitud de onda óptica» de extremo a extremo, transfiriendo y controlando paquetes sin conversión eléctrica. IOWN extiende la tecnología fotónica más allá de la capa de red hasta dispositivos y niveles de semiconductores. NTT apunta a una reducción de 1/100 en el consumo de energía, un aumento de 125× en la capacidad de transmisión y una reducción de 1/200 en la latencia extremo a extremo.
Los costes de procesamiento del NAT caen desde la raíz
Eliminar la conversión eléctrica hace desaparecer la latencia y el calor de la conversión. La barrera del número de sesiones que enfrenta CGNAT podría aliviarse significativamente. La causa raíz de «NAT es lento» estando en la capa física en lugar del protocolo se vuelve evidente de nuevo.
La vida útil de IPv4 puede extenderse aún más
Paradójicamente, si APN se generaliza, la situación de «con NAT todavía va bien» puede persistir aún más tiempo. Pero eliminar el cuello de botella de procesamiento significa que más dispositivos pueden manejarse con menos equipos. Con el consumo de energía cayendo drásticamente, la estructura de costes operativos de la infraestructura cambiará.
Un avance en un eje diferente al del diseño de direcciones
El debate IPv4-o-IPv6, 8-octetos-o-128-bits trata sobre el espacio de direcciones y la lógica de enrutamiento. IOWN/APN trae un avance en un eje diferente — velocidad de transferencia física, consumo de energía y latencia.
El diseño de protocolos y la evolución de la infraestructura física avanzan en pistas separadas. Si APN crea una «base que maneja cualquier protocolo rápido y con baja latencia», entonces IPv4, IPv6 o cualquier nuevo esquema de direcciones puede funcionar sobre él — más opciones, más flexibilidad.
NTT apunta a uso práctico en la década de 2030, y por ahora sigue en fase de investigación y demostración. Pero el concepto de «procesar señales que llegan por fibra óptica sin volver a convertirlas a electricidad — todo óptico» claramente tiene el potencial de transformar fundamentalmente los cimientos físicos de internet. Vale la pena seguirlo junto al debate sobre el diseño de direcciones.